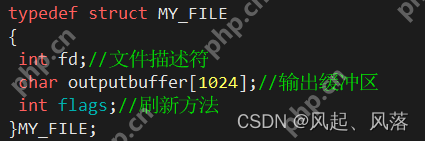
1、管道
我們了解到進程是獨立的,但有時進程間需要進行通信。那么,如何實現進程間的通信呢?
進程間通過文件的內核緩沖區實現資源共享,這個過程無需磁盤參與,因此設計了一種內存級的文件來專門實現進程間通信,這種內存級文件就是管道。管道是什么?
管道是unix中最古老的進程間通信形式,從一個進程連接到另一個進程的數據流稱為“管道”。管道的原理:
 必須先打開文件,然后創建子進程,不能先創建子進程再打開文件。這個過程利用的是子進程會繼承父進程相關資源的特性。
必須先打開文件,然后創建子進程,不能先創建子進程再打開文件。這個過程利用的是子進程會繼承父進程相關資源的特性。
為什么父進程在打開文件時必須以“讀寫”方式打開,不能只讀或只寫?因為父進程打開文件,創建子進程后,父子進程必須有一個寫,一個讀,不能兩個都讀或兩個都寫。管道不需要路徑,也就不需要名字,所以稱為匿名管道。
 上面的操作只是讓父子進程看到了同一份資源,但還沒有實現通信。這個內存資源由操作系統提供,因此進程間通信也應通過操作系統實現,即調用系統調用。
上面的操作只是讓父子進程看到了同一份資源,但還沒有實現通信。這個內存資源由操作系統提供,因此進程間通信也應通過操作系統實現,即調用系統調用。
#include <iostream> #include <unistd.h> #include <sys/types.h> #include <sys/wait.h> using namespace std; int main(){ //1、創建管道 int fds[2] = {0}; int n = pipe(fds); if (n != 0) { cerr << "pipe error" << endl; return -1; } //2、創建子進程 pid_t id = fork(); if (id < 0) { cerr << "fork error" << endl; return -1; } else if (id == 0) { //子進程 //3、關閉不需要的fd close(fds[0]);//0是讀 int cnt = 0; while (true) { string message = "hello world, hello "; message += to_string(getpid()); message += ", "; message += to_string(cnt++); write(fds[1], message.c_str(), message.size()); sleep(1); } exit(0); } else { //父進程 close(fds[1]);//1是寫 char buffer[1024]; while (true) { ssize_t n = read(fds[0], buffer, 1024); if (n > 0) { buffer[n] = 0; cout << "father, message: " << buffer << endl; } } } return 0; }
子進程寫,父進程讀。看待父子進程就像看待文件一樣。在上面子進程sleep的過程中,父進程在做什么呢?在阻塞等待。父進程在讀完子進程的數據后,操作系統就不讓父進程讀了,讓其進入阻塞狀態,等待子進程再次寫入。這是為了保護共享資源,防止子進程寫了一半父進程就讀,或者父進程讀了一半子進程就寫。這個過程是管道內部自動完成的。
現象:
管道為空且管道正常,read會阻塞(read是一個系統調用)。管道為滿(管道資源是有限的)且管道正常,write會阻塞。管道寫端關閉且讀端繼續,讀端讀到0,表示讀到文件結尾。管道讀端關閉且寫端繼續,操作系統會終止寫入的進程。
 特性:
特性:
面向字節流。不關心對面是如何寫的,按需讀取。用來進行具有血緣關系的進程進行IPC,常用于父子進程。文件的生命周期隨進程,管道也是。單向數據通信。管道自帶同步互斥等保護機制。
2、進程池退出
當關閉寫端,讀端讀到0,表示讀到文件結尾,則結束進程。即將父進程所有的讀端關閉,則相應的子進程就會結束,最后再由父進程等待回收。
void CleanProcessPool(){ //virsion1 for (auto &c : _channels) { c.Close(); } for (auto &c : _channels) { pid_t rid = waitpid(c.GetId(), nullptr, 0); if (rid > 0) { cout << "child " << rid << " exit" << endl; } } }
為什么要分開關閉讀端和等待子進程,不能關一個等一個嗎?
 根據上面的分析,所有的子進程的file_struct都會指向第一個管道,越往后的子進程指向的管道越多。所以我們只是把master的file_struct中指向管道關閉,這個管道還有其他子進程的file_struct指向,因此讀端不會讀到0,子進程不會退出,就會一直阻塞。解決這個問題有兩種辦法:
根據上面的分析,所有的子進程的file_struct都會指向第一個管道,越往后的子進程指向的管道越多。所以我們只是把master的file_struct中指向管道關閉,這個管道還有其他子進程的file_struct指向,因此讀端不會讀到0,子進程不會退出,就會一直阻塞。解決這個問題有兩種辦法:
1、倒著關閉 因為通過分析可知,越早創建的管道指向越多,最后一個管道只被指向一次,只要將最后一個進程關閉,則前面的所有管道被指向都會少1,因此倒著關閉就不會出現阻塞的問題。
//virsion2 for (int i = _channels.size()-1; i >= 0; i--) { _channels[i].Close(); pid_t rid = waitpid(_channels[i].GetId(), nullptr, 0); if (rid > 0) { cout << "child " << rid << " exit" << endl; } }
2、在子進程中關閉所有歷史fd 因為父進程的3號文件描述符總為空,子進程只有3號文件描述符指向管道。在這之前子進程繼承父進程對之前的管道的指向,所以只需要在子進程中把這些指向全部關掉就行。

// 3、建立通信信道 if (id == 0) { //關閉歷史fd for (auto &c : _channels) { c.Close(); } // 子進程 //close(pipefd[1]); //dup2(pipefd[0], 0); // 子進程從標準輸入讀取 //_work(); //exit(0); }
3、命名管道
我們知道,匿名管道的原理是讓父子進程看到同一份資源,而父子進程看到同一份資源,是因為子進程繼承了父進程的資源。所以不難得出,匿名管道兩端必須是父子進程。而如果我們想在任意進程之間建立管道呢?首先可以肯定的是這任意兩個進程之間也要能看到同一份資源,因為是任意進程之間,所以這個資源不能繼承而來,因此就牽扯出了命名管道。

 命名管道的原理:為什么叫做命名管道,因為有名字,是真實存在的文件,既然是真實存在的文件,就一定有路徑+文件名,而路徑+文件名具有唯一性。這樣不同的進程可以用同一個文件系統路徑標志同一個資源,也就是不同的進程看到了同一個資源。命名管道和普通文件的區別:這么看來命名管道和普通文件好像除了創建方式不同外也沒多大區別,而普通文件好像也能實現進程間通信,但是普通文件有兩個問題,我們往普通文件中寫入的數據會被刷新到磁盤中保存,另外普通文件也沒有被特殊保護,也就是我們可以往里寫大量的數據,在寫的過程中也有可能被其他進程讀,這兩個問題是命名管道需要重點處理的,所以命名管道和普通文件有很大的區別,是特殊設計的。這個命名管道,該由誰創建?公共資源:一般要讓指定的一個進程現行創建。一個進程創建&&使用,另一個進程獲取&&使用。
命名管道的原理:為什么叫做命名管道,因為有名字,是真實存在的文件,既然是真實存在的文件,就一定有路徑+文件名,而路徑+文件名具有唯一性。這樣不同的進程可以用同一個文件系統路徑標志同一個資源,也就是不同的進程看到了同一個資源。命名管道和普通文件的區別:這么看來命名管道和普通文件好像除了創建方式不同外也沒多大區別,而普通文件好像也能實現進程間通信,但是普通文件有兩個問題,我們往普通文件中寫入的數據會被刷新到磁盤中保存,另外普通文件也沒有被特殊保護,也就是我們可以往里寫大量的數據,在寫的過程中也有可能被其他進程讀,這兩個問題是命名管道需要重點處理的,所以命名管道和普通文件有很大的區別,是特殊設計的。這個命名管道,該由誰創建?公共資源:一般要讓指定的一個進程現行創建。一個進程創建&&使用,另一個進程獲取&&使用。
4、共享內存
共享內存區是最快的IPC形式。一旦這樣的內存映射到共享它的進程的地址空間,這些進程間數據傳遞不再涉及到內核,換句話說是進程不再通過執行進入內核的系統調用來傳遞彼此的數據。
 共享內存 = 共享內存的內核數據結構 + 內存塊。讓兩個進程通過各自的虛擬地址空間,映射同一塊物理內存,叫做共享內存。共享內存的本質還是讓不同的進程看到同一個資源。
共享內存 = 共享內存的內核數據結構 + 內存塊。讓兩個進程通過各自的虛擬地址空間,映射同一塊物理內存,叫做共享內存。共享內存的本質還是讓不同的進程看到同一個資源。
 IPC_CEEAT:單獨使用,如果shm不存在則創建,如果存在則獲取。保證調用進程就能拿到共享內存。IPC_CEEAT | IPC_EXCL:組合使用,如果不存在則創建,如果存在則返回錯誤。只要成功,一定是新的共享內存。key為什么必須要用戶傳入,為什么內核自己不生成?
IPC_CEEAT:單獨使用,如果shm不存在則創建,如果存在則獲取。保證調用進程就能拿到共享內存。IPC_CEEAT | IPC_EXCL:組合使用,如果不存在則創建,如果存在則返回錯誤。只要成功,一定是新的共享內存。key為什么必須要用戶傳入,為什么內核自己不生成?
任意進程間是獨立的,由某一個進程內生成key,其他的進程是拿不到的。理論上用戶可以隨意設置key,只要保證不沖突就可,為了保證key的唯一性有函數來減小沖突的概率。
 定義全局的key,讓進程間通過絕對路徑都能看到,由某個進程設置進內核中,則其他進程也能夠得到。所以在應用層面,不同進程看到同一份共享內存是通過唯一路徑+項目ID來確定的,類似命名管道也是通過文件路徑+文件名來確定的。
定義全局的key,讓進程間通過絕對路徑都能看到,由某個進程設置進內核中,則其他進程也能夠得到。所以在應用層面,不同進程看到同一份共享內存是通過唯一路徑+項目ID來確定的,類似命名管道也是通過文件路徑+文件名來確定的。
 在OS看來,由shmget函數創建的共享內存是OS創建的,所以共享內存的生命周期隨內核。和文件不同,文件的生命周期隨進程。所以共享內存一旦創建出來,要么由用戶主動釋放,要么OS重啟。
在OS看來,由shmget函數創建的共享內存是OS創建的,所以共享內存的生命周期隨內核。和文件不同,文件的生命周期隨進程。所以共享內存一旦創建出來,要么由用戶主動釋放,要么OS重啟。
共享內存的管理指令:
ipcs -m:查看共享內存信息ipcrm -m shmid:刪除共享內存shmid VS key:
shmid:僅供用戶使用的shm標識符(類似文件描述符fd)key:僅供內核區分不同shm唯一性的標識符(類似文件地址)除了指令刪除shm,還可以通過函數刪除:
 共享內存也有權限。
共享內存也有權限。
| 共享內存的特點:
不需要調用系統調用,通信速度快。讓兩個進程在各自的用戶空間共享內存塊,是真正的共享資源,但是不像管道,共享內存沒有任何保護。共享內存的保護機制,需要用戶自己完成。
 本篇文章的分享就到這里了,如果您覺得在本文有所收獲,還請留下您的三連支持哦~
本篇文章的分享就到這里了,如果您覺得在本文有所收獲,還請留下您的三連支持哦~